CDC – Change Data Capture
Introdução
Change Data Capture (CDC) é uma técnica que identifica e registra todas as mudanças (inserções, atualizações e exclusões) feitas em uma fonte de dados, como um banco de dados relacional, e transmite essas mudanças para outros sistemas, possibilitando uma sincronização em tempo real. Essa abordagem é fundamental para várias arquiteturas de dados modernas que necessitam de informações atualizadas e consistentes entre sistemas distintos.
Benefícios
CDC traz uma série de benefícios que vão além da simples movimentação de dados. Os principais benefícios podem ser observados na lista abaixo.
- Redução de carga no sistema fonte, capturando apenas as mudanças e evitando leituras de dados massivas, o que resulta em menor custo de infraestrutura.
- Replicação de dados em tempo real, eliminando a latência que geralmente existe em processos de ETL tradicionais.
- Capacidade de rastrear alterações para auditoria, backup e reprocessamento em outras plataformas.
- Atualizações contínuas de data lakes e data warehouses, alimentando sistemas analíticos com dados atuais.
Principais técnicas
A implementação de CDC pode ser realizada de diferentes maneiras, cada uma com vantagens e limitações específicas. Conhecer essas alternativas ajuda a selecionar a solução mais adequada para o contexto de cada organização. As técnicas mais comuns estão apresentadas a seguir.
- Leitura de logs de transações: capta mudanças diretamente nos logs de transações, método utilizado por ferramentas como o Debezium.
- Colunas de timestamp: uso de uma coluna que registra a última modificação em cada linha. Ideal para sistemas que não possuem logs transacionais detalhados.
- Gatilhos (triggers): uso de gatilhos para registrar mudanças nas tabelas, embora possa impactar a performance.
- Diferenciação de snapshots: compara snapshots tirados periodicamente. É uma abordagem mais pesada e menos precisa.
Técnicas
Binlog (Log de Transações)
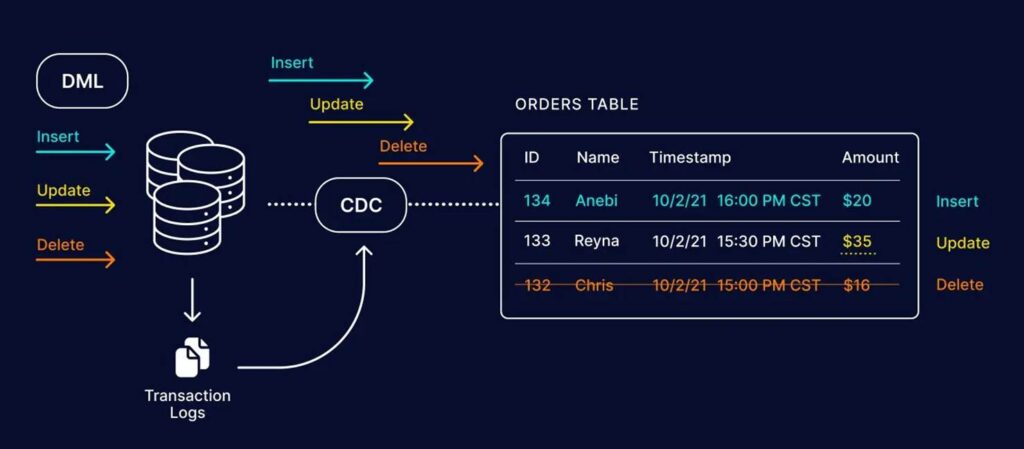
O binlog, ou log de transações, é um arquivo que registra todas as operações feitas no banco de dados. Bancos como MySQL (binlog) e PostgreSQL (WAL) possuem logs transacionais que podem ser monitorados em tempo real para capturar mudanças. Essa abordagem é eficiente e precisa, pois capta toda alteração feita nos dados, mas exige acesso aos logs e permissões de leitura. A desvantagem é que nem todos os bancos têm logs de transação tão detalhados, e a configuração pode exigir ajustes na infraestrutura.
Coluna de Timestamp
Consiste na criação de uma coluna que registra a última alteração feita em cada linha de uma tabela. Ao consultar apenas as linhas alteradas desde a última execução, o sistema captura as mudanças incrementais. Essa técnica é simples e aplicável em qualquer banco de dados, porém não captura exclusões de dados e exige que todas as tabelas monitoradas incluam essa coluna.
Triggers
Os triggers ou gatilhos são funções definidas no banco de dados que executam ações quando um evento específico ocorre (como uma inserção, atualização ou exclusão). Com CDC, os triggers podem ser configurados para registrar essas alterações em uma tabela de histórico. Embora eficiente, esse método é geralmente evitado devido ao impacto de performance e à complexidade de manutenção.
Diff entre Snapshots
Consiste na criação de snapshots periódicos dos dados e na comparação entre eles para identificar mudanças. É um método trabalhoso e com maior impacto no sistema, pois requer processamento intensivo, sendo utilizado apenas quando outras abordagens de CDC não estão disponíveis.
Ferramentas
Abaixo algumas das principais ferramentas de Change Data Capture do mercado.
- Debezium: Ferramenta open-source que usa logs de transação para capturar mudanças em tempo real. Suporta bancos como MySQL, PostgreSQL, MongoDB, e outros, e é integrada ao Kafka, o que facilita a transmissão de dados em pipelines de dados distribuídos.
Oracle GoldenGate: Ferramenta proprietária da Oracle para replicação e integração de dados em tempo real, compatível com vários sistemas de banco de dados.
StreamSets: Plataforma de integração que inclui componentes para CDC em diversos bancos e fontes de dados.
Qlik Replicate (Attunity): Solução robusta de CDC usada para replicação e sincronização de dados entre bancos de dados.
Amazon DMS e Azure Data Factory: Soluções de CDC oferecidas nas respectivas plataformas de nuvem para replicação e sincronização de dados entre serviços.
Airbyte: O Airbyte é uma plataforma open-source para integração de dados que oferece suporte a CDC através de diversos conectores, inclusive com monitoramento de logs de transação para bancos como MySQL e PostgreSQL. É uma opção flexível e expansível, com uma interface amigável que facilita a criação de pipelines de dados. O Airbyte tem uma ampla biblioteca de conectores e se destaca pela comunidade ativa e pela possibilidade de customização.
Striim: O Striim é uma plataforma de integração de dados em tempo real que combina CDC com análises de streaming e processamento de eventos. Suporta várias fontes de dados, como bancos de dados relacionais, e pode transmitir dados para diversas plataformas, incluindo nuvens como AWS, Azure e Google Cloud. Sua arquitetura robusta permite a replicação de dados em grande escala e processamento em tempo real, sendo popular em casos de uso que requerem insights instantâneos a partir dos dados.
Embora existam muitas ferramentas, focaremos no Debezium nesse artigo, uma popular opção de código aberto construída sobre o Kafka Connect, para ilustrar uma implementação prática.
Kafka Connector
O Kafka Connector é uma das funcionalidades principais do Kafka Connect, uma ferramenta da plataforma Apache Kafka projetada para simplificar e automatizar a integração entre o Kafka e outros sistemas, como bancos de dados, data warehouses, sistemas de armazenamento em nuvem e muito mais. O Kafka Connect funciona como uma camada de integração distribuída e escalável, que utiliza conectores especializados para transferir dados de forma confiável entre sistemas.
Como o Kafka Connect funciona
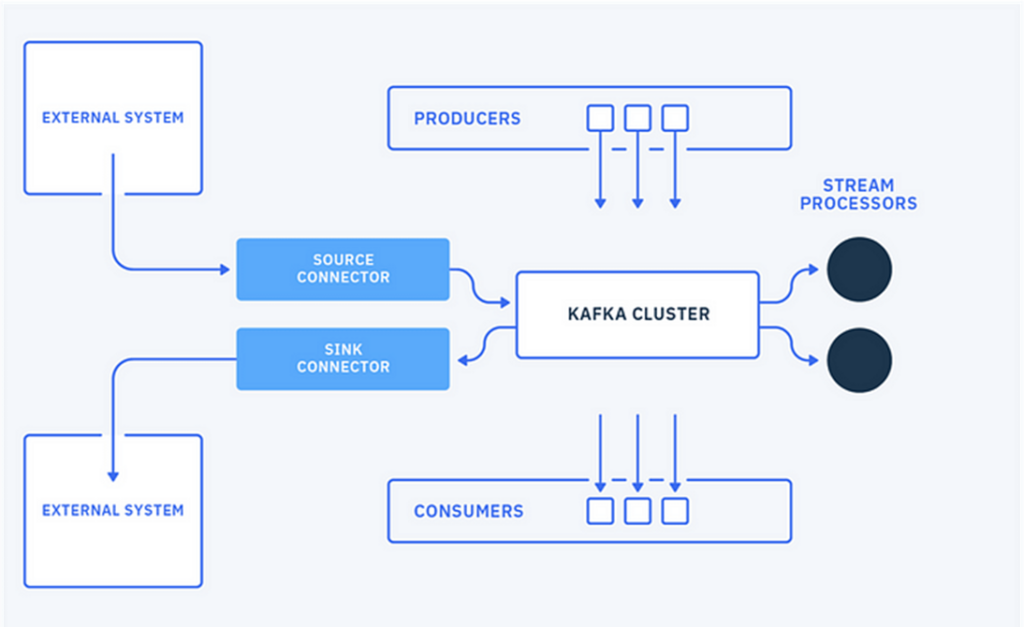
O Kafka Connect usa conectores, que são plugins especializados para cada tipo de sistema ou fonte de dados, divididos em duas categorias:
Source Connectors: Capturam dados de uma fonte externa e os publicam em tópicos do Kafka.
Sink Connectors: Consomem dados de tópicos Kafka e os escrevem em um sistema de destino.
Os conectores são configurados por meio de arquivos de configuração JSON ou APIs REST, onde é possível definir a fonte ou destino de dados, informações de autenticação, configurações de replicação e transformações opcionais para adequar os dados ao formato desejado.
Arquitetura do Kafka Connect
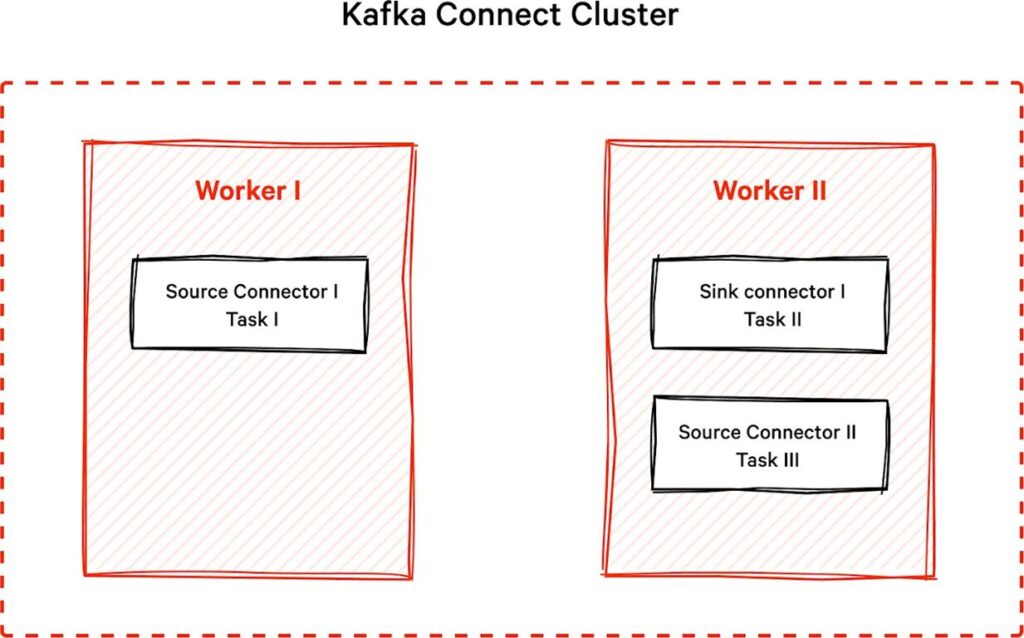
A arquitetura do Kafka Connect é composta por workers, que são instâncias executando conectores de forma distribuída. Isso permite que o Kafka Connect:
- Escale horizontalmente conforme a carga de dados aumenta.
- Seja tolerante a falhas: se um worker falhar, outro pode assumir as tarefas.
- Centralize a configuração e monitoramento dos conectores.
Os dados são processados em blocos chamados de tasks, que distribuem a carga de trabalho entre workers e possibilitam o processamento paralelo.
“Nem tudo são flores” (limitações)
Opções limitadas
Há menos de 20 tipos diferentes de conectores no Kafka Connect. Se um conector genérico não for adequado, você deve desenvolver um personalizado. Da mesma forma, o Kafka Connect fornece apenas um conjunto básico de transformações, e você também pode ter que escrever suas transformações personalizadas. Isso pode aumentar o tempo e o esforço necessários para a implementação.
Complexidade de configuração
As configurações do Kafka Connect rapidamente se tornam complexas, especialmente ao lidar com vários conectores, tarefas e transformações. Isso pode dificultar o gerenciamento, a manutenção e a solução de problemas do sistema. Também é desafiador integrar o Kafka Connect com outras ferramentas que sua organização já pode estar usando. Isso cria uma barreira à adoção e retarda o processo de implementação.
Suporte limitado para tratamento de erros
O foco principal do Kafka é o streaming de dados, o que resulta em capacidades limitadas de tratamento de erros integrados. A natureza distribuída e as potenciais interdependências entre vários componentes do Kafka aumentam a complexidade, dificultando a descoberta da causa raiz do erro. Você pode ter que implementar mecanismos personalizados de tratamento de erros, o que pode ser demorado e nem sempre tão confiável quanto as capacidades integradas fornecidas por outras ferramentas de integração de dados e ETL.
Recuperar-se graciosamente de erros complexos também é desafiador no Kafka, pois pode não haver um caminho claro para retomar o processamento de dados após a ocorrência de um erro. Isso pode levar a ineficiências e exigir mais intervenção manual para restaurar as operações normais.
Problemas de desempenho
A maioria dos aplicativos requer pipelines de dados de alta velocidade para casos de uso em tempo real. No entanto, dependendo do tipo de conector e do volume de dados, o Kafka Connect pode introduzir alguma latência no seu sistema. Isso pode não ser adequado se o seu aplicativo não tolerar atrasos.
“Mas há solução” (melhores práticas)
Mesmo com essas limitações, seria incorreto afirmar que o Kafka Connect não é uma boa escolha; ele tem inúmeros benefícios que superam em muito suas limitações.
O Kafka Connect é uma ferramenta poderosa para construir pipelines de dados escaláveis, mas garantir uma implementação bem-sucedida e adoção operacional requer seguir as melhores práticas. Aqui estão algumas dicas e conselhos para evitar erros e alcançar o sucesso com o Kafka Connect.
Planeje seu pipeline
Antes de iniciar o processo de implementação, determine as fontes e destinos dos seus dados e garanta que seu pipeline seja escalável e possa lidar com volumes de dados crescentes. Além disso, certifique-se de provisionar a infraestrutura adequadamente. O Kafka Connect requer uma infraestrutura escalável e confiável para desempenho ideal. Use uma arquitetura baseada em cluster com recursos suficientes para lidar com a carga do pipeline de dados e garanta que sua infraestrutura esteja altamente disponível.
Use um Schema Registry
Utilizar um Schema Registry no Kafka Connect pode ser benéfico, pois permite armazenamento e gerenciamento centralizados de schemas. Isso ajuda a manter a consistência do schema em todos os sistemas, reduz a probabilidade de corrupção de dados e simplifica a evolução do schema.
Configurar para desempenho
É importante projetar e configurar seu Kafka Connect para escala e desempenho futuros. Por exemplo, você pode implementar uma estratégia de particionamento adequada para distribuir seus dados uniformemente entre as partições. Isso ajudará seu cluster Kafka Connect a gerenciar um alto volume de dados de forma eficaz. Da mesma forma, você pode usar um formato de serialização eficiente, como Avro ou Protobuf, para transferi-lo mais rapidamente na rede.
Monitoramento
O monitoramento é essencial para garantir o funcionamento tranquilo do seu pipeline de dados. Use ferramentas de monitoramento para rastrear o desempenho da sua implantação do Kafka Connect e identificar e resolver rapidamente quaisquer problemas.
Opções para monitoramento do Kafka Connect:
- Prometheus + Grafana
- Confluent Control Center
- Lenses.io
- Elastic Stack (ELK)
- Metrics API do Kafka Connect
Dead Letter Topic (DLT)
Você também pode considerar implementar uma Dead Letter Topic (DLT) como uma rede de segurança para capturar e manipular quaisquer mensagens que falhem repetidamente durante as novas tentativas, garantindo que elas não sejam perdidas, e em cima disso assentar uma estratégia de reprocessamento para todas as mensagem da DLT.
Debezium
O Debezium é uma plataforma open-source de CDC construída sobre o Kafka Connect. Ele lê diretamente os logs de transação de bancos de dados, capturando mudanças em tempo real e publicando esses eventos em tópicos Kafka. Isso permite a integração desses dados com diversos consumidores e facilita o desenvolvimento de pipelines de dados em tempo real.
Arquitetura
O Debezium é executado como um conector Kafka Connect e utiliza um conector específico para cada tipo de banco de dados. Quando configurado, o Debezium lê os logs de transação e transmite as mudanças para tópicos no Kafka, onde os consumidores podem acessar esses eventos. Esse processo permite que o Debezium seja altamente escalável e fácil de integrar com outras aplicações e sistemas.
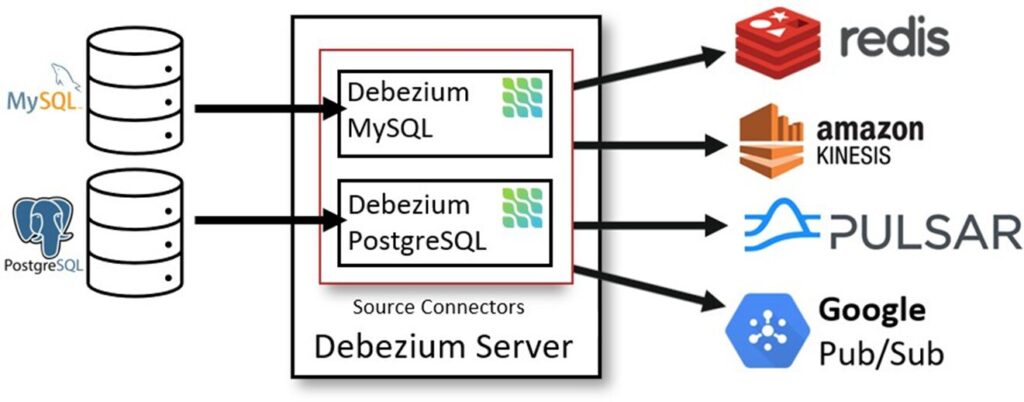
Benefícios do Debezium:
Open-source e flexível: sendo gratuito e extensível.
Escalável com Kafka: ideal para sistemas distribuídos e de alta demanda.
Consistência e confiabilidade: captura mudanças sem intervenção na estrutura de dados.
Transformações no Debezium (SMTs)
As Single Message Transforms (SMTs) no Debezium são transformações que podem ser aplicadas em mensagens individuais durante o processamento de Change Data Capture (CDC). Estas transformações ocorrem após a leitura dos dados da fonte e antes da escrita no kafka ou sistema de destino.
Tipos de Transformações
Transformações de Roteamento
Permitem modificar como as mensagens são encaminhadas dentro do sistema.
RegexRouter: Modifica o tópico de destino usando expressões regulares
ByteBufferConverter: Converte campos entre diferentes formatos de bytes
TopicRouter: Redireciona mensagens para tópicos específicos baseado em condições
Transformações de Conteúdo
Modificam o conteúdo das mensagens.
- ExtractField: Extrai um campo específico da mensagem
- InsertField: Adiciona campos estáticos ou dinâmicos
- ReplaceField: Substitui valores de campos existentes
- MaskField: Mascara dados sensíveis
DropFields: Remove campos específicos
Transformações de Valor
Alteram os valores dentro das mensagens.
ValueToKey: Move um valor para a chave da mensagem
ValueToTimestamp: Converte um campo em timestamp
Cast: Converte tipos de dados
TimestampConverter: Converte formatos de timestamp
Transformações Estruturais
Modificam a estrutura das mensagens.
- Flatten: Converte estruturas aninhadas em estrutura plana
- HoistField: Eleva campos aninhados para o nível superior
- WrapField: Encapsula campos em uma nova estrutura
Casos de Uso Comuns
- Mascaramento de Dados Sensíveis
{
"transforms": "maskFields",
"transforms.maskFields.type": "org.apache.kafka.connect.transforms.MaskField$Value", "transforms.maskFields.fields": "creditCard,ssn",
"transforms.maskFields.replacement": "****"
}
2. Renomeação de Campos
{
"transforms": "RenameField",
"transforms.RenameField.type": "org.apache.kafka.connect.transforms.ReplaceField$Value",
"transforms.RenameField.renames": "oldName:newName"
}
3. Adição de Metadados
{
"transforms": "insertSourceDetails",
"transforms.insertSourceDetails.type": "org.apache.kafka.connect.transforms.InsertField$Value", "transforms.insertSourceDetails.static.field": "source_database",
"transforms.insertSourceDetails.static.value": "production_db"
}
Considerações de Performance
- Ordem de Execução: As transformações são executadas na ordem em que são listadas
- Impacto no Desempenho: Cada transformação adiciona overhead ao processamento
- Complexidade: Transformações complexas podem afetar a latência
Boas Práticas
- Minimizar Transformações: Use apenas as transformações necessárias
- Ordem Eficiente: Coloque transformações mais seletivas primeiro
- Monitoramento: Monitore o impacto das transformações no desempenho
- Testes: Valide transformações em ambiente de desenvolvimento
- Documentação: Mantenha documentação clara das transformações aplicadas
Limitações
- Algumas transformações podem não preservar tipos de dados originais
- Transformações complexas podem afetar a garantia de ordem das mensagens
- Nem todas as transformações são compatíveis entre si
- Algumas transformações podem não funcionar com todos os formatos de serialização
Recomendações de Uso
1. Análise de Requisitos
- Identifique claramente as necessidades de transformação
- Avalie o impacto no sistema como um todo
2. Implementação
- Comece com transformações simples
- Teste cada transformação individualmente
- Documente todas as transformações aplicadas
3. Manutenção
- Monitore o desempenho regularmente
- Revise periodicamente a necessidade de cada transformação
- Mantenha as transformações atualizadas com novas versões do Debezium
Casos de Uso
O CDC pode ser aplicado em uma variedade de cenários para otimizar a integração e replicação de dados em tempo real, alguns dos quais, referidos abaixo.
- Outbox Pattern (monitora e encaminha eventos para um Kafka (por ex.), garantindo que as mensagens sejam publicadas, mesmo com falhas, e desacoplando a lógica da entrega de mensagens.)
- Espelhamento de dados (migração monolito -> microsserviço)
- Replicação de dados (Integração / microsserviços -> microsserviços)
- Auditoria de dados
- Análises em tempo real (dashboards e relatórios em tempo real)
- Cache de dados (Fazer cache de certos dados do Postgres no Redis por ex)
- Dados para consulta (disponibilizar dados em um motor de busca como o ElasticSearch)
- CQRS (disponibilizando os dados de Command em fontes de dados de Query)
- etc…
Uso Prático do Debezium
Preparação da Infra
Garanta que o Docker e o Docker Compose estejam instalados e funcionando, pois vamos precisar subir o Kafka, o Zookeeper, o Debezium Connector e o Banco de dados.
Criando o Docker Compose
Crie um arquivo docker-compose.yml com o seguinte conteúdo:
version: '3.8' services: postgres: image: debezium/postgres:16 ports: - "5433:5432" environment: - POSTGRES_DB=inventory - POSTGRES_USER=postgres - POSTGRES_PASSWORD=postgres command: postgres -c wal_level=logical networks: debezium-network: aliases: - postgres zookeeper: image: confluentinc/cp-zookeeper:7.5.0 ports: - "2181:2181" environment: ZOOKEEPER_CLIENT_PORT: 2181 ZOOKEEPER_TICK_TIME: 2000 networks: debezium-network: aliases: - zookeeper kafka: image: confluentinc/cp-kafka:7.5.0 depends_on: - zookeeper ports: - "9092:9092" environment: KAFKA_BROKER_ID: 1 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka:9093,EXTERNAL://localhost:9092 KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT KAFKA_LISTENERS: INTERNAL://0.0.0.0:9093,EXTERNAL://0.0.0.0:9092 KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1 networks: debezium-network: aliases: - kafka kafka-connect: image: debezium/connect:2.5 ports: - "8083:8083" depends_on: - kafka - postgres environment: BOOTSTRAP_SERVERS: kafka:9093 GROUP_ID: 1 CONFIG_STORAGE_TOPIC: connect_configs OFFSET_STORAGE_TOPIC: connect_offsets STATUS_STORAGE_TOPIC: connect_statuses KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE: "false" CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE: "false" CONNECT_REST_ADVERTISED_HOST_NAME: kafka-connect networks: debezium-network: aliases: - kafka-connect networks: debezium-network: driver: bridge
Rodando os serviços
Na pasta onde foi criado o docker-compose.yml , execute (no terminal):
# dependendo de como seu docker foi instalado, # você vai precisar usar o 'sudo' antes do commando docker compose up
Configuração do Debezium Connector
Envie uma configuração JSON para o endpoint REST do Kafka Connect para configurar o conector do Debezium:
# 1. Primeiro, verifique se o Debezium Connect está rodando:
curl -X GET http://localhost:8083/connectors
# 2. Criando o connector
# 2.1. Comando principal para criar o connector (SEM transformação / comece por esse):
curl -X POST http://localhost:8083/connectors \
-H "Content-Type: application/json" \
-d '{
"name": "inventory-clientes-connector", "config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "postgres", "database.port": "5433", "database.user": "postgres", "database.password": "postgres", "database.dbname": "inventory", "database.server.name": "dbserver1", "table.include.list": "public.clientes", "topic.prefix": "inventory", "schema.include.list": "public", "decimal.handling.mode": "precise", "plugin.name": "pgoutput"
}
}'
# 2.2. Comando principal para criar o connector (COM transformação):
curl -X POST http://localhost:8083/connectors \
-H "Content-Type: application/json" \
-d '{
"name": "inventory-clientes-connector", "config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "postgres", "database.port": "5433", "database.user": "postgres", "database.password": "postgres", "database.dbname": "inventory", "database.server.name": "dbserver1", "table.include.list": "public.clientes", "topic.prefix": "inventory", "schema.include.list": "public", "decimal.handling.mode": "precise", "plugin.name": "pgoutput",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState", "transforms.unwrap.drop.tombstones": "false", "transforms.unwrap.delete.handling.mode": "rewrite"
}
}'
# Exemplo de uma configuração de um connector de Sink para Redis
curl -X POST http://localhost:8083/connectors \
-H "Content-Type: application/json" \
-d '{
"name": "redis-sink", "config": {
"connector.class": "com.github.jcustenborder.kafka.connect.redis.RedisSinkConnector", "redis.hosts": "redis:6379",
"topics": "inventory.public.clientes",
"tasks.max": "1",
"key.converter": "org.apache.kafka.connect.json.JsonConverter", "value.converter": "org.apache.kafka.connect.json.JsonConverter", "key.converter.schemas.enable": "true", "value.converter.schemas.enable": "true"
}
}'
# 3. Para verificar o status do connector:
curl -X GET http://localhost:8083/connectors/inventory-clientes-connector/status
Explicação dos Parâmetros:
name: Nome do conector, usado para gerenciamento (pode ser personalizado).
connector.class: Especifica o conector Debezium para PostgreSQL (io.debezium.connector.postgresql.PostgresConnector).
tasks.max: Número máximo de tarefas paralelas para o conector (pode aumentar dependendo da carga).
database.hostname: Endereço do servidor do PostgreSQL.
database.port: Porta em que o PostgreSQL está rodando (padrão é 5432).
database.user e database.password: Usuário e senha para acessar o banco (o usuário precisa de permissões para ler os logs de transação).
database.dbname: Nome do banco de dados a ser monitorado.
database.server.name: Nome lógico do servidor; será usado como prefixo para os tópicos Kafka criados para as tabelas.
slot.name: Nome do slot de replicação. Estemudanças nos dados em tempo real usando a replicação lógica.
plugin.name: Define o plugin de replicação lógica. Para PostgreSQL 10+ e Debezium, o pgoutput é recomendado.
table.include.list: Lista de tabelas para monitorar (no formato schema.tabela ). Caso queira monitorar várias tabelas, você pode separar os nomes com vírgulas.
publication.name: Nome da publicação de replicação lógica que captura as alterações na tabela especificada. database.history.kafka.bootstrap.servers: Endereço do Kafka onde o histórico do esquema será armazenado, essencial para Debezium entender a estrutura das tabelas e mudanças de esquema.
database.history.kafka.topic: Tópico Kafka onde o histórico do esquema será armazenado.
Monitorando as Mudanças
kafka-console-consumer
Ferramenta da stack do Kafka para fazer o consumo de tópicos diretamente no console.
# Console Consumer - verifica as mensagens no tópico sudo docker exec -it cdc-kafka kafka-console-consumer \ --bootstrap-server localhost:9092 \ --topic inventory.public.clientes \ --from-beginning
Plugin Big Data Tools para IntelliJ
Provectus Kafka UI
GitHub – provectus/kafka-ui: Open-Source Web UI for Apache Kafka Management
kafka-ui: image: provectuslabs/kafka-ui:latest container_name: cdc-kafka-ui ports: - 8080:8080 depends_on: - kafka environment: DYNAMIC_CONFIG_ENABLED: 'true' networks: debezium-network: aliases: - kafka-ui
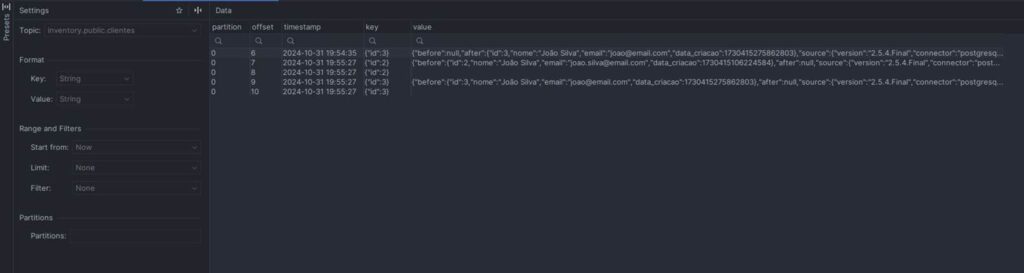
“Vendo a mágica acontecer”
Criar a tabela
-- Cria a tabela CREATE TABLE inventory.public.clientes ( id SERIAL PRIMARY KEY, nome VARCHAR(50), email VARCHAR(50), data_criacao TIMESTAMP DEFAULT CURRENT_TIMESTAMP ); -- Verifica se tem dados SELECT * FROM inventory.public.clientes;
Conectando o Consumer
Você pode conectar o consumer padrão do Kafka para consumir as mensagens assim que entrarem no tópico:
# Console Consumer - verifica as mensagens no tópico sudo docker exec -it cdc-kafka kafka-console-consumer \ --bootstrap-server localhost:9092 \ --topic inventory.public.clientes \ --from-beginning
Ou usar uma das ferramentas listadas acima (plugin do IntelliJ ou Kafka UI).
Testando o funcionamento
Inserindo dados
INSERT INTO inventory.public.clientes (nome, email) VALUES ('João Silva 1', 'joao1@email.com');
INSERT INTO inventory.public.clientes (nome, email) VALUES ('João Silva 2', 'joao2@email.com'); INSERT INTO inventory.public.clientes (nome, email) VALUES ('João Silva 3', 'joao3@email.com');
Atualizando dados
UPDATE inventory.public.clientes SET nome = 'Pedro Silva', email = 'pedro.silva@email.com' WHERE id = 1; UPDATE inventory.public.clientes SET nome = 'José Silva', email = 'jose.silva@email.com' WHERE id = 2; UPDATE inventory.public.clientes SET nome = 'Jacó Silva', email = 'jaco.silva@email.com' WHERE id = 3;
Excluindo dados
-- Deleta o registro DELETE FROM inventory.public.clientes WHERE id = 1; DELETE FROM inventory.public.clientes WHERE id = 2; DELETE FROM inventory.public.clientes WHERE id = 3;
Alterando a quantidade de informações de replicação
-- Altera a quantidade de infos que estão disponíveis para decodificação lógica em caso de eventos UPDATE e DELETE. ALTER TABLE inventory.public.clientes REPLICA IDENTITY FULL;
Execute novamente os testes (insert, update e delete) após ajustar o nível de replicação.
Solucionando Problemas
# Visualizando os logs sudo docker compose --file debezium-docker-compose.yml logs kafka sudo docker compose --file debezium-docker-compose.yml logs zookeeper sudo docker compose --file debezium-docker-compose.yml logs postgres sudo docker compose --file debezium-docker-compose.yml logs kafka-connect # Inspecionando a rede sudo docker network inspect debezium-network
Conclusão
O Change Data Capture é uma técnica amplamente utilizada pelo mercado, nas suas diversas formas, nas suas diversas ferramentas. É especialmente útil em migrações de dados e de sistema, facilitando o estrangulamento de um monolito ou replicando alguns dados de um microsserviço para outro, ou simplesmente aplicado ao padrão Outbox.
Nesse cenário o Debezium se apresenta como uma ótima ferramenta pra isso, baseado na já testada e comprovada plataforma Connect do Kafka. Mas como em qualquer cenário ele tem seus pontos de atenção, de risco e de desvantagens. É essencial que as equipes técnicas estejam cientes tanto do potencial quanto das limitações da ferramenta, garantindo decisões arquiteturais bem fundamentadas.


